JVM內存管理 數據處理與存儲服務的基石
在構建高性能、高可靠的數據處理與存儲支持服務時,Java虛擬機(JVM)的內存管理機制是核心基礎。它不僅是應用運行的載體,更是數據處理效率、系統穩定性和服務擴展性的決定性因素。深入理解并優化JVM內存管理,對于現代數據密集型服務至關重要。
一、JVM內存區域與數據處理角色
JVM內存主要劃分為堆(Heap)、棧(Stack)、方法區(Method Area,元空間)、程序計數器(Program Counter Register)和本地方法棧(Native Method Stack)。其中,堆內存是數據處理服務的“主戰場”。
- 堆內存(Heap):所有對象實例和數組都在堆上分配。對于數據處理服務而言,這包括了從數據源加載的原始數據、處理過程中的中間結果、緩存對象以及最終準備存儲或輸出的數據集合。其進一步細分為:
- 新生代(Young Generation):存放新創建的對象。大多數數據處理任務會頻繁創建和銷毀大量短期對象(如迭代中的臨時對象),這些對象的生命周期短暫,GC(垃圾回收)在這里最為頻繁,主要采用復制算法。
- 老年代(Old Generation):存放存活時間較長的對象。例如,緩存的熱點數據、數據庫連接池對象、長期駐留的核心數據結構(如全局配置、索引映射等)。這里采用標記-清除或標記-整理算法進行GC。
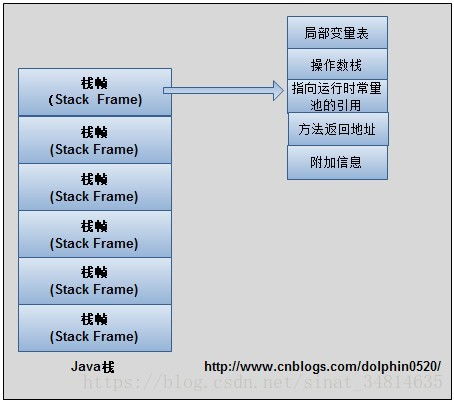
- 棧內存(Stack):存儲局部變量、操作數棧、方法出口等信息。每個線程獨享一個棧。數據處理中的方法調用鏈、遞歸計算、局部臨時變量都依賴于棧的高效運作。
- 元空間(Metaspace):存儲類的元數據信息,如類名、方法代碼、常量池、靜態變量等。大量使用反射、動態代理或頻繁加載/卸載類的數據處理框架(如Spark、Flink的任務調度)需關注此區域,防止內存泄漏。
二、垃圾回收(GC)與數據處理性能
GC是JVM內存管理的核心,其策略直接影響數據處理服務的吞吐量和延遲。
- 吞吐量優先:對于離線批處理、大數據計算等場景,追求單位時間內處理的數據量最大。通常選擇Parallel Scavenge(新生代)配合Parallel Old(老年代)等組合,充分利用多核資源進行并行GC,最大化應用線程的CPU時間。
- 低延遲優先:對于實時流處理、在線事務處理(OLTP)、高并發API服務等,要求每次GC停頓時間(STW)極短。CMS(Concurrent Mark Sweep)和G1(Garbage-First)收集器,以及最新的ZGC和Shenandoah,都致力于將STW時間控制在毫秒甚至亞毫秒級別,保證數據處理流程的平滑性。
- 大內存與混合工作負載:對于擁有超大堆(如數十GB至數TB)的數據處理服務,G1、ZGC等收集器通過劃分Region、并發標記整理等機制,能更好地平衡吞吐與延遲。
三、內存管理優化實踐
- 合理設置堆大小:通過
-Xms和-Xmx設置初始和最大堆大小,避免動態調整帶來的性能開銷。通常設置為相同值以鎖定堆大小。根據數據處理的數據量峰值和對象生命周期特點,合理分配新生代與老年代的比例(-XX:NewRatio)。
- 對象生命周期管理:
- 避免創建不必要的對象:在循環內謹慎創建對象,重用對象(使用對象池)。
- 及時釋放引用:處理完的數據集合、大型緩存條目應及時置為
null,幫助GC識別。
- 小心使用
finalize方法:它可能導致對象晉升延遲和GC效率低下。
- 選擇與調優GC收集器:根據服務類型(批處理/實時流)和SLA要求(延遲/吞吐)選擇合適的收集器,并針對性地調整參數,如并行線程數、并發階段觸發閾值、最大停頓時間目標等。
- 監控與分析:利用JVM工具(如jstat, jmap, jstack)和APM(應用性能管理)工具持續監控堆內存使用情況、GC頻率與耗時、對象創建速率等關鍵指標。結合Heap Dump分析內存泄漏和對象分布。
- 配合外部存儲服務:對于超出JVM堆內存管理能力的海量數據,JVM內存應作為高速緩存和計算緩沖區。數據處理服務需與外部存儲(如Redis、Memcached做緩存;Kafka、Pulsar做消息緩沖;HDFS、S3做持久化存儲)緊密協作,通過高效的數據分片、流水線處理和緩存策略,將數據在JVM內存與外部存儲間有序流動,從而擴展整體的數據處理能力。
###
JVM內存管理是數據處理與存儲支持服務高效、穩定運行的底層引擎。從內存區域的合理利用,到垃圾回收策略的精妙選擇,再到持續的性能監控與調優,每一個環節都深刻影響著數據處理的吞吐量、延遲和資源利用率。開發者與架構師需要將JVM內存管理視為系統設計的一部分,結合具體的數據處理模式與業務需求,構建出既穩健又敏捷的數據服務基石。
如若轉載,請注明出處:http://www.568dy.cn/product/64.html
更新時間:2026-06-01 23:36:29