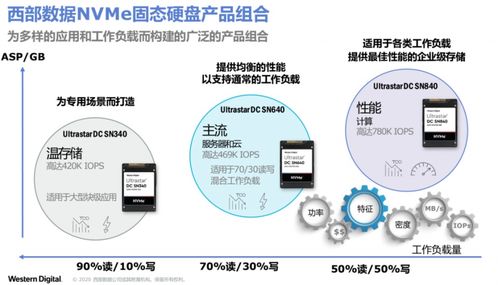
大數(shù)據(jù)基礎 數(shù)據(jù)存儲組件及處理與存儲支持服務概覽
在當今數(shù)據(jù)驅(qū)動的時代,大數(shù)據(jù)技術已成為企業(yè)獲取洞察、優(yōu)化決策的核心引擎。一個健壯的大數(shù)據(jù)體系架構(gòu)依賴于高效、可擴展的數(shù)據(jù)存儲組件,以及強大的數(shù)據(jù)處理與存儲支持服務。本文將系統(tǒng)性地介紹大數(shù)據(jù)領域的關鍵數(shù)據(jù)存儲組件,并闡述支撐其高效運行的處理與存儲服務。
一、 核心數(shù)據(jù)存儲組件
大數(shù)據(jù)存儲組件根據(jù)數(shù)據(jù)特性、訪問模式和業(yè)務需求,主要分為以下幾類:
- 分布式文件系統(tǒng)
- 代表:HDFS (Hadoop Distributed File System)
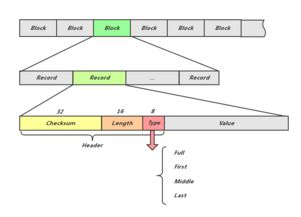
- 核心思想:將超大文件分割成塊(Block),分散存儲在多臺廉價商用服務器上,提供高吞吐量的數(shù)據(jù)訪問。它遵循“一次寫入,多次讀取”的模式,非常適合存儲海量原始數(shù)據(jù),是Hadoop生態(tài)的基石。
- 特點:高容錯性、高吞吐量、可線性擴展、成本低廉。
2. NoSQL數(shù)據(jù)庫
為應對海量半結(jié)構(gòu)化、非結(jié)構(gòu)化數(shù)據(jù)的高并發(fā)讀寫需求而誕生,放棄了傳統(tǒng)關系型數(shù)據(jù)庫的部分特性(如強一致性、復雜事務),以換取更高的擴展性和靈活性。
- 鍵值存儲 (Key-Value Store):如 Redis(內(nèi)存型,極高性能)、DynamoDB(云托管)。通過唯一的鍵來訪問數(shù)據(jù),簡單高效,常用于緩存、會話存儲。
- 列式存儲 (Wide-Column Store):如 HBase(基于HDFS)、Cassandra。數(shù)據(jù)按列族存儲,適合稀疏數(shù)據(jù),支持海量數(shù)據(jù)的隨機、實時讀寫。
- 文檔數(shù)據(jù)庫 (Document Store):如 MongoDB、Couchbase。以JSON/BSON等格式存儲半結(jié)構(gòu)化文檔,模式靈活,易于開發(fā)。
- 圖數(shù)據(jù)庫 (Graph Database):如 Neo4j。專門存儲實體(節(jié)點)和關系(邊),擅長處理復雜的關聯(lián)查詢,如社交網(wǎng)絡、推薦系統(tǒng)。
3. NewSQL數(shù)據(jù)庫與分布式SQL引擎
試圖兼顧NoSQL的擴展性與傳統(tǒng)SQL數(shù)據(jù)庫的ACID事務和強一致性。
- NewSQL:如 Google Spanner、TiDB。重新設計的分布式關系型數(shù)據(jù)庫。
- 分布式SQL引擎:如 Apache Hive(將SQL轉(zhuǎn)化為MapReduce/Tez/Spark作業(yè))、Presto/ Trino、Impala(MPP架構(gòu),交互式查詢)。它們本身不直接存儲數(shù)據(jù),而是作為計算引擎對底層HDFS或?qū)ο蟠鎯χ械臄?shù)據(jù)執(zhí)行快速SQL查詢。
- 對象存儲
- 代表:AWS S3、阿里云OSS、MinIO。
- 核心思想:將數(shù)據(jù)作為不可變的對象(Object)連同元數(shù)據(jù)一起存儲在一個扁平的命名空間中(桶Bucket)。通過RESTful API訪問。
- 特點:無限擴展、高耐久性、成本低廉,已成為云上數(shù)據(jù)湖(Data Lake)的事實標準存儲。
- 消息隊列/日志存儲
- 代表:Apache Kafka。
- 角色:雖然主要作為實時數(shù)據(jù)流平臺,但其持久化、分區(qū)的提交日志(Commit Log)架構(gòu)使其成為出色的流數(shù)據(jù)“存儲”中間件,用于解耦生產(chǎn)者和消費者,緩沖海量事件數(shù)據(jù)。
二、 數(shù)據(jù)處理與存儲支持服務
僅有存儲組件還不夠,需要一系列服務來管理、優(yōu)化和保障數(shù)據(jù)生命周期的各個環(huán)節(jié)。
- 數(shù)據(jù)處理與計算框架
- 批處理:Apache Hadoop MapReduce(開創(chuàng)性,但較慢)、Apache Spark(內(nèi)存計算,性能卓越,支持批流統(tǒng)一)。
- 流處理:Apache Storm(早期)、Apache Flink(低延遲、高吞吐、狀態(tài)精確一次處理)、Spark Streaming(微批處理)。
* 交互式分析:Presto/Trino、Apache Druid(實時OLAP)。
這些框架是數(shù)據(jù)的“加工廠”,從存儲組件中讀取數(shù)據(jù),進行計算分析,再將結(jié)果寫回存儲。
- 資源管理與協(xié)調(diào)服務
- 資源管理:Apache YARN(Hadoop 2.0+的核心,負責集群資源調(diào)度與管理)、Kubernetes(容器編排,日益成為大數(shù)據(jù)工作負載的新調(diào)度平臺)。
- 協(xié)調(diào)服務:Apache ZooKeeper(提供分布式一致性服務,如配置管理、命名服務、分布式鎖,是HBase、Kafka等組件的依賴)。
- 數(shù)據(jù)編排與元數(shù)據(jù)管理
- 數(shù)據(jù)編排:Apache Airflow、DolphinScheduler。用于定義、調(diào)度和監(jiān)控復雜的數(shù)據(jù)處理工作流(Pipeline)。
- 元數(shù)據(jù)管理:Apache Atlas、DataHub。提供數(shù)據(jù)血緣(Lineage)、分類、治理功能,幫助理解數(shù)據(jù)的來源、變化和流向,是數(shù)據(jù)治理的核心。
- 存儲優(yōu)化與緩存服務
- 存儲格式:列式存儲格式如 Parquet、ORC,能極大提升查詢性能并降低存儲成本。
- 數(shù)據(jù)壓縮:如Snappy、LZO、Zstandard,節(jié)省存儲空間和網(wǎng)絡I/O。
- 緩存層:如 Alluxio(內(nèi)存速度的虛擬分布式存儲系統(tǒng)),在計算框架和底層存儲(如S3、HDFS)間提供緩存加速層。
5. 云上托管服務
云廠商(AWS, Azure, GCP, 阿里云等)提供了上述幾乎所有組件的全托管服務(如EMR、Databricks、BigQuery、Cosmos DB),極大降低了運維復雜度,讓用戶更專注于數(shù)據(jù)價值挖掘。
###
大數(shù)據(jù)的數(shù)據(jù)存儲生態(tài)是多元且互補的。HDFS/對象存儲常作為數(shù)據(jù)湖的持久化層;NoSQL數(shù)據(jù)庫應對特定場景的高性能讀寫;分布式SQL引擎提供便捷的數(shù)據(jù)查詢?nèi)肟冢欢鳮afka則連接實時數(shù)據(jù)流。這一切都由YARN/K8s等資源管理器調(diào)度,由Airflow等工具編排任務,并由Atlas等平臺治理。理解各組件的定位與協(xié)同關系,是構(gòu)建高效、可靠大數(shù)據(jù)平臺的基礎。在實際架構(gòu)選型中,需緊密結(jié)合數(shù)據(jù)特征、業(yè)務場景、性能要求與成本約束進行綜合決策。
如若轉(zhuǎn)載,請注明出處:http://www.568dy.cn/product/53.html
更新時間:2026-06-01 07:32:11